Amazon S3
Connect Semaphor to your Amazon S3 bucket
Prerequisites
Before proceeding, ensure you have the following:
- An AWS account
- A Semaphor account
- An S3 bucket with required data
Create a Cross-Account IAM Role
To allow Semaphor to access your S3 bucket securely, you need to create a cross-account IAM role.
- Follow the official official AWS guide on creating a cross-account IAM role.
- Ensure that the role trusts Semaphor’s AWS account (defined in step 3).
Assign Permissions to the IAM Role
Once the IAM role is created, you must grant it permissions to access your S3 bucket.
- Navigate to IAM in the AWS Console.
- Open the IAM role and go to the Permissions tab.
- Attach the following policy to grant Semaphor access to your bucket:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:GetObject", "s3:ListBucket"],
"Resource": ["arn:aws:s3:::my-s3-bucket", "arn:aws:s3:::my-s3-bucket/*"]
}
]
}Replace my-s3-bucket with the actual name of your S3 bucket.
Define Trust Relationships
Semaphor needs permission to assume the IAM role. To set this up:
- Go to the Trust relationships tab of the IAM role.
- Add the following Trust Policy to allow Semaphor’s AWS account to assume the role:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::756808986636:root"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": "my_project_id"
}
}
}
]
}Replace my_project_id with the actual project ID.
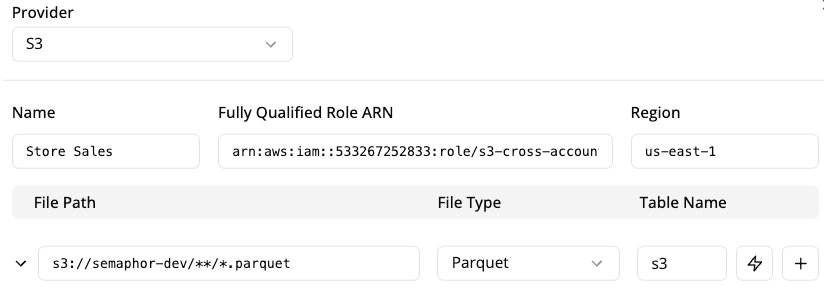
Configure the Connection in Semaphor
After setting up the IAM role:
- Copy the fully qualified role ARN from the AWS Console. Example:
arn:aws:iam::756808986636:role/semaphor-access-roleIn the Semaphor console, enter:
- The Role ARN
- The AWS region where your S3 bucket is located
Verify the Connection
To confirm that Semaphor can access your S3 bucket:
- Click the
⚡️ TestConnection button in the Semaphor console. - If successful, you will see a green check mark (✓) indicating a valid connection.
Supported File Formats
Semaphor currently supports .parquet and .csv file formats.
You can configure Semaphor to scan your bucket using wildcard * notation. The wildcard notation **/*.parquet instructs Semaphor to recursively retrieve all files in the root / prefix that end with .parquet.
Analyze your data
Once the connection is established, you can start analyzing your S3 files as if they are database tables.
SELECT * from s3 limit 10;Parsing Fields
Semaphor uses duckdb to auto detect fields which uses the ISO 8601 format format by default for timestamps, dates and times. Unfortunately, not all dates and times are formatted using this standard.
If your Parquet file was generated by a tool like Pandas, make sure datetime64 columns are saved as TIMESTAMP and not as strings.
You can convert to date in Pandas before saving:
df['date'] = pd.to_datetime(df['date'], format='%m/%d/%y')